Contents
Overview
The concept of a single point of failure has been around since the early days of complex systems, with pioneers like Nikola Tesla and Thomas Edison recognizing the importance of redundancy in electrical systems. Today, companies like Netflix and Uber rely on distributed systems and cloud computing to minimize SPOFs, while researchers at institutions like MIT and Stanford explore new ways to design fault-tolerant systems. For example, the Google File System, developed by Google engineers like Sanjay Ghemawat and Howard Gobioff, is designed to handle failures of individual nodes without disrupting the entire system.
⚙️ How It Works
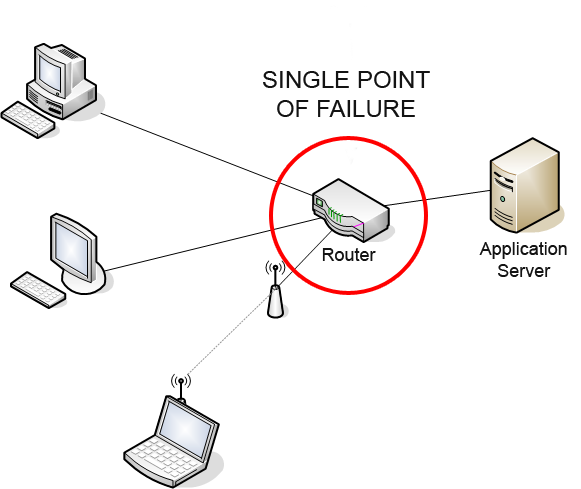
A single point of failure can be a hardware component, a software module, or even a human operator. In the case of a power grid, a single point of failure could be a critical transmission line or a generator. In a software system, it could be a database or a critical algorithm. Companies like Facebook and Twitter have experienced outages due to SPOFs in their systems, highlighting the importance of designing systems with redundancy and fail-safes. Experts like Andrew Ng and Fei-Fei Li emphasize the need for AI systems to be designed with fault tolerance in mind, to prevent SPOFs from causing catastrophic failures.
🌍 Cultural Impact
The cultural impact of single points of failure is significant, with outages and failures making headlines and affecting millions of people. The 2003 Northeast blackout, which affected over 50 million people, was caused by a single point of failure in the power grid. Similarly, the 2011 Amazon Web Services outage, which affected companies like Reddit and Quora, was caused by a SPOF in Amazon's cloud infrastructure. Researchers at institutions like Harvard and Yale study the social and economic impacts of SPOFs, while companies like IBM and Cisco develop solutions to mitigate them.
🔮 Legacy & Future
The legacy of single points of failure is a reminder of the importance of designing systems with redundancy and fault tolerance in mind. As systems become increasingly complex and interconnected, the risk of SPOFs increases. Experts like Nick Bostrom and Elon Musk warn of the potential risks of SPOFs in critical systems like artificial intelligence and nuclear power plants. To mitigate these risks, companies like Microsoft and Amazon are investing in research and development of new technologies, such as blockchain and quantum computing, to create more resilient and fault-tolerant systems. For example, the Microsoft Azure platform uses a combination of redundant hardware and software components to minimize SPOFs and ensure high availability.
Key Facts
- Year
- 1960s
- Origin
- United States
- Category
- technology
- Type
- concept
Frequently Asked Questions
What is a single point of failure?
A single point of failure is a component in a system that, if it fails, will cause the entire system to fail.
Why are single points of failure undesirable?
Single points of failure are undesirable because they can cause significant disruptions to a system, leading to losses in productivity, revenue, and reputation.
How can single points of failure be mitigated?
Single points of failure can be mitigated through the use of redundancy, fault tolerance, and high availability design principles.
What are some examples of single points of failure?
Examples of single points of failure include critical transmission lines in a power grid, databases in a software system, and human operators in a manufacturing process.
How do companies like Google and Amazon mitigate single points of failure?
Companies like Google and Amazon mitigate single points of failure through the use of redundant systems, distributed architectures, and fault-tolerant design principles.