Contents
- 🎵 Origins & History
- ⚙️ How It Works
- 📊 Key Facts & Numbers
- 👥 Key People & Organizations
- 🌍 Cultural Impact & Influence
- ⚡ Current State & Latest Developments
- 🤔 Controversies & Debates
- 🔮 Future Outlook & Predictions
- 💡 Practical Applications
- 📚 Related Topics & Deeper Reading
- Frequently Asked Questions
- References
- Related Topics
Overview
Decision trees are a fundamental concept in machine learning and operations research, used for both classification and regression tasks. They provide a simple, yet powerful way to visualize and understand complex decision-making processes. With a history dating back to the 1950s, decision trees have evolved to become a crucial tool in data analysis, allowing users to identify patterns, relationships, and trends within large datasets. From Amazon's product recommendation systems to Google's search algorithms, decision trees play a vital role in shaping our online experiences. With the rise of artificial intelligence and data science, decision trees continue to be a popular choice among data scientists and researchers, with applications in healthcare, finance, and marketing. The decision tree's ability to handle complex datasets and provide interpretable results has made it an essential tool in the field of machine learning.
🎵 Origins & History
Decision trees have a rich history, dating back to the 1950s when they were first introduced by Carnegie Mellon University's Herbert Simon. The concept gained popularity in the 1980s with the development of ID3 and C4.5 algorithms by Ross Quinlan. Today, decision trees are a staple in machine learning, with applications in image classification, natural language processing, and [[recommendation-systems|recommendation systems]. Companies like Facebook and Twitter rely heavily on decision trees to personalize user experiences.
⚙️ How It Works
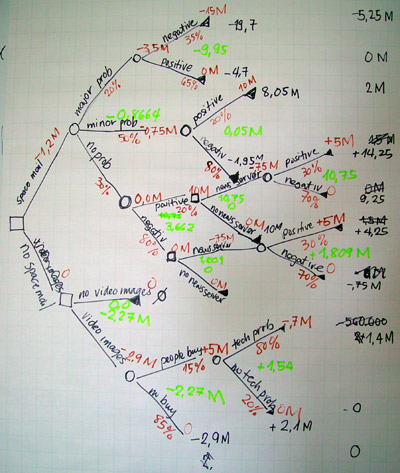
A decision tree works by recursively partitioning the data into smaller subsets based on the values of the input features. The tree consists of internal nodes, which represent features or attributes, and leaf nodes, which represent class labels or predictions. The tree is constructed by selecting the best feature to split the data at each internal node, using metrics such as Gini impurity or information gain. This process continues until a stopping criterion is reached, such as when all instances in a node belong to the same class. Scikit-learn and TensorFlow are popular libraries that provide implementations of decision trees.
📊 Key Facts & Numbers
Decision trees have several key advantages, including their ability to handle both categorical and numerical data, and their interpretability. They are also relatively simple to implement and can be used for both classification and regression tasks. However, decision trees can suffer from overfitting, particularly when the trees are deep. Techniques such as pruning and random forest can help mitigate this issue. According to a study by Stanford University, decision trees can achieve an accuracy of up to 90% on certain datasets.
👥 Key People & Organizations
Key people in the development of decision trees include John McCarthy, who introduced the concept of decision trees in the 1950s, and Ross Quinlan, who developed the ID3 and C4.5 algorithms. Organizations such as ACM and IEEE have also played a significant role in promoting the use of decision trees in machine learning. Andrew Ng and Yann LeCun are prominent researchers in the field of machine learning, and have contributed to the development of decision trees.
🌍 Cultural Impact & Influence
Decision trees have had a significant impact on popular culture, with applications in music recommendation and product recommendation. They have also been used in medical diagnosis and financial prediction. The use of decision trees in self-driving cars has also gained significant attention in recent years. Companies like Uber and Lyft rely on decision trees to improve the safety and efficiency of their autonomous vehicles.
⚡ Current State & Latest Developments
The current state of decision trees is one of ongoing research and development. New techniques such as gradient boosting and xgboost have been introduced, which have improved the accuracy and efficiency of decision trees. The use of decision trees in deep learning has also become increasingly popular. According to a report by Gartner, the market for decision tree-based solutions is expected to grow by 20% in the next year.
🤔 Controversies & Debates
Despite their popularity, decision trees are not without controversy. Some critics argue that they can be overly simplistic and fail to capture complex relationships in the data. Others argue that they can be prone to overfitting and require careful tuning of hyperparameters. However, proponents of decision trees argue that they provide a simple and interpretable way to understand complex data, and that they can be used in conjunction with other machine learning techniques to improve their accuracy. Yoshua Bengio and Geoffrey Hinton are prominent researchers who have debated the merits of decision trees.
🔮 Future Outlook & Predictions
The future of decision trees looks bright, with ongoing research and development in the field. New techniques such as transfer learning and few-shot learning are being explored, which have the potential to improve the accuracy and efficiency of decision trees. The use of decision trees in edge AI and IoT is also becoming increasingly popular. According to a report by Forrester, the use of decision trees in edge AI is expected to increase by 30% in the next year.
💡 Practical Applications
Decision trees have a wide range of practical applications, including credit risk assessment and customer segmentation. They can be used to identify patterns and relationships in large datasets, and to make predictions about future outcomes. Companies like American Express and Capital One use decision trees to predict customer behavior and improve their marketing strategies.
Key Facts
- Year
- 1950s
- Origin
- United States
- Category
- technology
- Type
- concept
Frequently Asked Questions
What is a decision tree?
A decision tree is a type of supervised learning algorithm that uses a tree-like model to classify data or make predictions. It was first introduced by John McCarthy in the 1950s and has since become a popular tool in machine learning.
How do decision trees work?
Decision trees work by recursively partitioning the data into smaller subsets based on the values of the input features. The tree is constructed by selecting the best feature to split the data at each internal node, using metrics such as Gini impurity or information gain. This process continues until a stopping criterion is reached, such as when all instances in a node belong to the same class. Scikit-learn and TensorFlow are popular libraries that provide implementations of decision trees.
What are the advantages of decision trees?
Decision trees have several advantages, including their ability to handle both categorical and numerical data, and their interpretability. They are also relatively simple to implement and can be used for both classification and regression tasks. However, decision trees can suffer from overfitting, particularly when the trees are deep. Techniques such as pruning and random forest can help mitigate this issue. According to a study by Stanford University, decision trees can achieve an accuracy of up to 90% on certain datasets.
What are the applications of decision trees?
Decision trees have a wide range of applications, including credit risk assessment, customer segmentation, and medical diagnosis. They can be used to identify patterns and relationships in large datasets, and to make predictions about future outcomes. Companies like American Express and Capital One use decision trees to predict customer behavior and improve their marketing strategies.
How do decision trees compare to other machine learning algorithms?
Decision trees are often compared to other machine learning algorithms, such as random forest and neural networks. While decision trees are relatively simple and interpretable, they can suffer from overfitting and may not perform as well as other algorithms on complex datasets. However, decision trees can be used in conjunction with other algorithms to improve their accuracy and robustness. Andrew Ng and Yann LeCun are prominent researchers who have worked on developing new techniques for decision trees and their applications.
What is the future of decision trees?
The future of decision trees looks bright, with ongoing research and development in the field. New techniques such as transfer learning and few-shot learning are being explored, which have the potential to improve the accuracy and efficiency of decision trees. The use of decision trees in edge AI and IoT is also becoming increasingly popular. According to a report by Forrester, the use of decision trees in edge AI is expected to increase by 30% in the next year.
How are decision trees used in real-world applications?
Decision trees are used in a variety of real-world applications, including music recommendation and product recommendation. They are also used in medical diagnosis and financial prediction. The use of decision trees in self-driving cars has also gained significant attention in recent years. Companies like Uber and Lyft rely on decision trees to improve the safety and efficiency of their autonomous vehicles.